C++ mutex는 몇 개 알고 계신가요?
C++ mutex는 6개이다.
아래 글에서 mutex를 다뤘으니 볼드체로 된 3 가지만 알아볼 텐데, (나머지 2개는 조합이니 관심 있는 분은 개별로 알아보세요.) 이 mutex 들을 통해 아래 이슈에 대한 해결이 가능하게 된다.
1. lock 중에 lock을 호출하여 deadlock이 발생하는 문제 해결 방법은?
2. 공유데이터를 읽을 때 속도를 향상 시키는 방법은?
3. 한정된 시간에 lock에 예외를 발생시키는 방법은?
mutex(C++11), recursive_mutex(C++11), shared_mutex(C++17)
timed_mutex(C++11), recursive_timed_mutex(C++11), shared_timed_mutex(C++14)
2023.09.26 - [L C++] - [thread] race condition 예방 방법 : Mutex와 Semaphore
std::recursive_mutex (since C++11)
이전 글에서 경쟁 상태(race condition)를 막기 위해 mutex에 대해 설명을 했지만, mutex는 lock/ unlock을 반드시 pair에 맞춰서 사용해야 한다. 코드량이 방대해지면서 우리 의도와 다르게 lock 중에 lock이 호출되는 경우가 발생하기도 한다. deadlock (교착상태)
예제 1
mutex 소유자가 한번 더 lock을 하면서 이후코드가 실행이 불가능한 상태가 되는 프로그램 코드이다.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std::literals;
std::mutex m;
//std::recursive_mutex m;
int share_data = 0;
void foo()
{
m.lock();
m.lock();
share_data = 100;
std::cout << "using share_data" << std::endl;
m.unlock();
m.unlock();
}
int main()
{
std::thread t1(foo);
std::thread t2(foo);
t1.join();
t2.join();
}
deadlock은 어디에서 되었을까요? 🤔
👉 deadlock이 되었지만 어떻게 deadlock이 되었는지는 이해하고 넘어가자.
t1, t2 순으로 실행이 되니 t1의 foo 가 실행되면서 m.lock()를 호출하고, t2는 foo의 m.lock()에서 대기를 하게 된다. 하지만 뮤텍스 소유자가 lock 이후에 또 lock을 하면서 deadlock 상태가 된 것이다.
위 코드에서 아래내용면 변경해서 실행해 보자.
//as-is
std::mutex m;
//std::recursive_mutex m;
//to-be
//std::mutex m;
std::recursive_mutex m;
결과
using share_data
using share_data
deadlock이 발생하지 않고 정상적으로 실행이 된다.
std::recursive_mutex은
뮤텍스 소유자가 여러 번 lock 하는 것을 허용한다.
단, lock의 횟수만큼 unlock을 해야 한다.
예제 1을 보면 "누가 저렇게 코드를 실수할까?"란 생각이 할 수 있다. 그럼 아래와 같은 가상의 시나리오를 생각해 보자.
예제 2-1
Machine class는 공유 데이터(shared_data)를 쓰는 f1, f2 함수와 읽는 getShared_data 함수를 제공한다.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std::literals;
class Machine
{
int shared_data = 0;
public:
void f1()
{
shared_data = 100;
}
void f2()
{
shared_data = 200;
}
int getShared_data() { return shared_data;};
};
int main()
{
Machine m;
std::cout << "shared_data = " << m.getShared_data() << std::endl;
}
이후, 속도 향상을 위해서 f1, f2를 각각의 스레드로 동작하게 수정하면 다음과 같다.
예제 2-2
예제 2-1에서 f1, f2 함수를 스레드로 실행시키는 프로그램 코드이다.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std::literals;
class Machine
{
std::mutex m;
int shared_data = 0;
public:
void f1()
{
m.lock();
shared_data = 100;
m.unlock();
}
void f2()
{
m.lock();
shared_data = 200;
m.unlock();
}
int getShared_data() { return shared_data;};
};
int main()
{
Machine m;
std::thread t1(&Machine::f1, &m);
std::thread t2(&Machine::f2, &m);
t1.join();
t2.join();
std::cout << "shared_data = " << m.getShared_data() << std::endl;
}
f1, f2 함수를 각각 스레드로 호출을 할 때 데이터 액세스의 직렬화를 보장하기 위해 데이터에 쓰기 전 후에 lock/ unlock 처리를 하였다.(여기까진 문제가 없다.)
예제 2-3
이후 내부에 f1를 호출하는 f3을 추가하였고, 이것도 스레드로 실행해 보자.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std::literals;
class Machine
{
std::mutex m;
int shared_data = 0;
public:
void f1()
{
m.lock();
shared_data = 100;
m.unlock();
}
void f2()
{
m.lock();
shared_data = 200;
m.unlock();
}
void f3()
{
m.lock();
shared_data = 300; //공유자원을 쓰기위해 lock 중인데
f1(); // f1 내에서 lock이 다시 호출된다.
m.unlock();
}
int getShared_data() { return shared_data;};
};
int main()
{
Machine m;
std::thread t1(&Machine::f1, &m);
std::thread t2(&Machine::f2, &m);
std::thread t3(&Machine::f3, &m);
t1.join();
t2.join();
t3.join();
std::cout << "shared_data = " << m.getShared_data() << std::endl;
}
f3 내에서도 shared_data을 쓰기 때문에 f1, f2와 유사하게 함수 시작과 끝에 lock/unlock을 추가하였다. 하지만 f3 내에는 f1을 호출하고 있었는데 f1 내에서 lock을 호출하고 있어서 f3 실행 시 lock이 2번 호출된다.
void f1()
{
m.lock();
shared_data = 100;
m.unlock();
}
void f3()
{
m.lock();
shared_data = 300; //공유자원을 쓰기위해 lock 중인데
f1(); // f1 내에서 lock이 다시 호출된다.
m.unlock();
}
하나의 상황을 가정해 보았지만 함수 안에 어떤 로직들이 들어있는지 모르고 기존 동작 로직을 copy/paste를 하다 보면 로직 안에 lock을 호출하고 있는지는 일일이 확인해보지 않고는 알 수 없다. 이럴 때 recursive_mutex를 사용하면 내부에 lock/unlock 이 있더라도 내가 추가로 호출하는 lock 횟수만큼 unlock이 호출된다면 문제없이 사용할 수 있다.👍
주의: recursive_mutex는 deadlock 문제를 해결하는 만능 기술이 아니다. deadlock이 걸리는 원인도 모른 채 무조 건 mutex => recursive_mutex로 변경하여 해결하려고 해서는 안된다.
std::shared_mutex (since C++17)
생각해 봅시다.
만약 각각의 스레드에서 공유데이터를 읽기만 할 때 mutex 처리는 어떻게 해야 할까?
mutex를 사용하는 이유는 데이터 액세스를 직렬화하기 위해서이다. 만약 각각의 스레드에서 공유데이터를 읽기만 할 때는 굳이 데이터 액세스를 직렬화할 필요가 없다. 하지만 데이터를 써야 할 때는 읽으면 안 되고 반대로 읽을 때 써서도 안된다. 조건이 까다로워 보이지만 정리하면 다음과 같으며
@ 쓸 때 => 쓰기/읽기 금지
@ 읽을 때 => 쓰기 금지
@ 읽을 때 => 읽기 가능
위 조건을 만족하면서 동작이 가능하게 하는 기능을 shared_mutex에서 제공하고 있다.
예제 3
mutex를 사용하여 Writer 함수에서는 공유데이터(shared_data) 쓰기를, Reader 함수에서는 shared_data를 읽기만 하는 스레드를 실행시키는 프로그램 코드이다.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
#include <shared_mutex>
#include <string>
using namespace std::literals;
std::mutex m;
int share_data = 0;
void Writer()
{
while (1)
{
m.lock();
share_data = share_data + 1;
std::cout << "Writer : " << share_data << std::endl;
std::this_thread::sleep_for(1s);
m.unlock();
std::this_thread::sleep_for(10ms);
}
}
void Reader(const std::string& name)
{
while (1)
{
m.lock();
std::cout << "Reader(" << name << ") : " << share_data << std::endl;
std::this_thread::sleep_for(500ms);
m.unlock();
std::this_thread::sleep_for(10ms);
}
}
int main()
{
std::thread t1(Writer);
std::thread t2(Reader, "A");
std::thread t3(Reader, "B");
std::thread t4(Reader, "C");
t1.join();
t2.join();
t3.join();
t4.join();
}
공유데이터를 읽기만 하는 스레드에는 as-is를 to-be처럼 변경하고, 실행한 결과를 이전과 비교해 보자.
//as-is
std::mutex m;
//std::shared_mutex m;
...
void Reader(const std::string& name)
{
while (1)
{
m.lock();
std::cout << "Reader(" << name << ") : " << share_data << std::endl;
std::this_thread::sleep_for(500ms);
m.unlock();
std::this_thread::sleep_for(10ms);
}
}
//to-be
//std::mutex m;
std::shared_mutex m;
...
void Reader(const std::string& name)
{
while (1)
{
//m.lock();
m.lock_shared();
std::cout << "Reader(" << name << ") : " << share_data << std::endl;
std::this_thread::sleep_for(500ms);
//m.unlock();
m.unlock_shared();
std::this_thread::sleep_for(10ms);
}
}
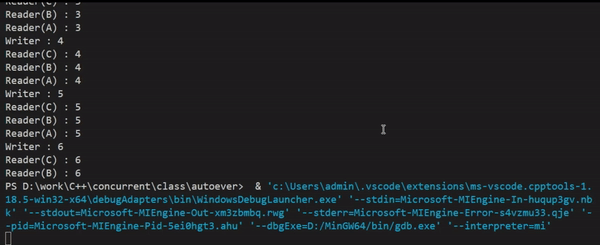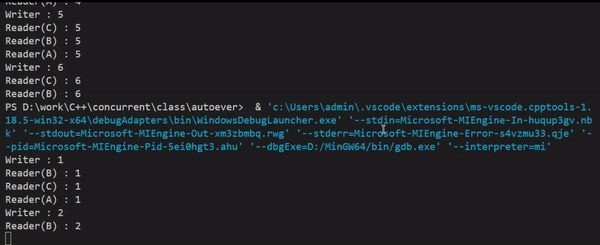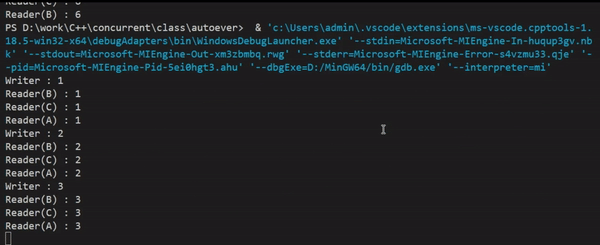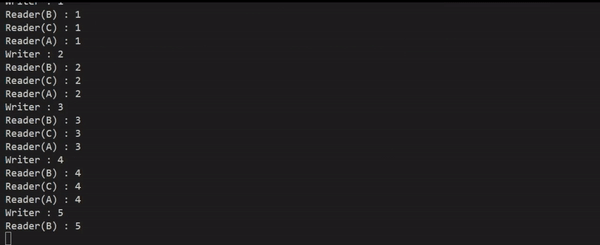
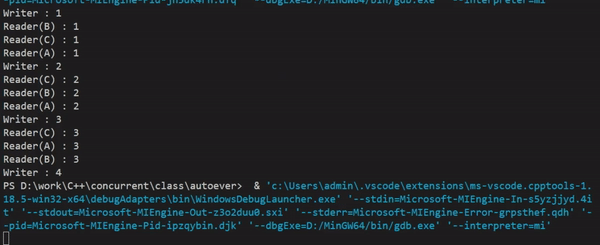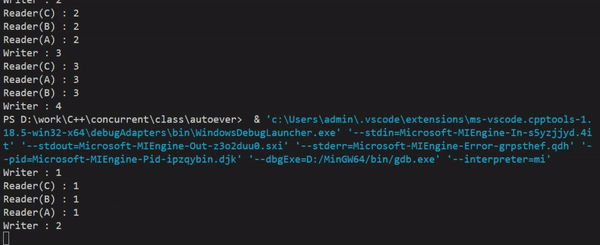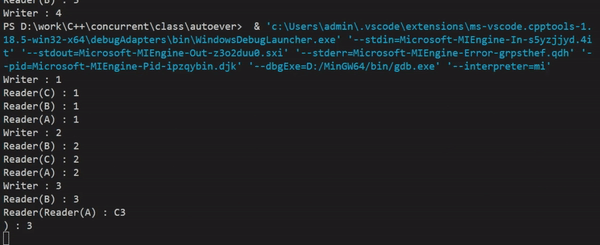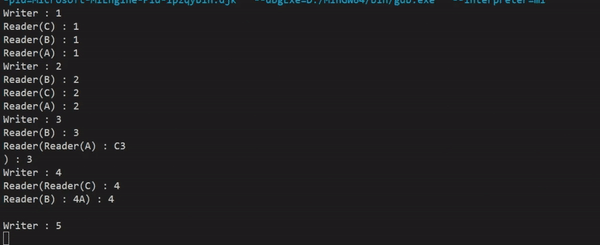
실행결과를 보면 쓸 때(Writer)는 읽기를 하지 않고, 읽을 때(Reader)는 동시에 접근이 가능하게 하여 스레드 간 공유 데이터를 읽기 위해 lock을 걸면서 지연되는 시간이 사라져, 처리속도가 향상된 것을 눈으로 확인할 수 있다.
중요코드 설명
shared_mutex 동작 방식
m.lock() : 하면 다른 스레드의 lock(), lock_shared()는 모두 대기
=> 쓰는 동안 "R/W 모두 금지"
m.lock_shared() : 다른 스레드의 lock() 은 대기
다른 스레드의 lock_shared() 은 대기 안 함
=> 읽은 동안은 "쓰기 금지", "읽기 가능"
// Write : lock(), unlock()
// Reader : lock_shared(), unlock_shared()
std::timed_mutex (since C++11)
생각해 봅시다.
공유데이터를 액세스 하는데 대기시간이 길어지면 성능이 저하된다. 이 때문에 마지노선을 두고 지연에 대한 예외 동작을 하게 하려면 어떻게 해야 할까?🤔
성능에 영향을 받아 데이터 액세스 대기 시간이 길어질 수 있다. 반드시 액세스를 해야 한다면 시간이 걸리더라도 대기를 해야 하겠지만 주기적으로 시도를 한다면 응답 대기 시간(timeout)이 있는 경우가 있다. 이럴 때 timed_mutex를 사용하여 대기 시간 초과에 대한 예외처리를 할 수 있다.
예제 4
timed_mutex를 이용하여 3초 안에 lock이 가능한지 판단하는 프로그램 코드이다.
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std::literals;
std::timed_mutex m;
int share_data = 0;
void foo()
{
if (m.try_lock_for(3s))
{
share_data = 100;
std::cout << "using share_data" << std::endl;
std::this_thread::sleep_for(4s);
m.unlock();
}
else
{
std::cout << "뮤텍스 획득 실패" << std::endl;
}
}
int main()
{
std::thread t1(foo);
std::thread t2(foo);
t1.join();
t2.join();
}
결과
using share_data
뮤텍스 획득 실패
중요코드 설명
std::timed_mutex는 lock()/ try_lock() 외에 아래 2개 멤버함수를 제공한다.
- m.try_lock_for(시간) : 시간 동안 대기
- m.try_lock_until(시간) : 시간 까지 대기
m.try_lock_for(3s)
이미 lock 이 되어 있으면 대기를 하고 있다가 3초 안데 소유권이 넘어오면 lock을 하고 true를 return, 넘어오지 않으면 false를 리턴한다.
첫 스레드에서 try_lock_for 실행 시 lock을 하고 두 번째 스레드는 try_lock_for 실행 시 이미 lock 중이라 대기를 하는데 첫 스레드의 unlock이 4초 뒤에 호출되기에 그 사이 대기시간인 3초가 초과되어 예외동작이 실행되었다.
참고
* 본 글에 예제 코드는 코드누리 교육을 받으면서 제공된 샘플코드를 활용하였습니다.
'L C++ > Concurrency' 카테고리의 다른 글
| [Concurrency] mutex의 lock/unlock 관리 도구 소개 (2/2) (2) | 2024.01.02 |
|---|---|
| [Concurrency] mutex의 lock/unlock 관리 도구 소개 (1/2) (4) | 2023.12.29 |
| [Concurrency] std::call_once - 중복 초기화 해소 기술 (0) | 2023.12.12 |
| [Concurrency] thread_local - thread 전용 변수 ✔ (0) | 2023.12.05 |
| [Concurrency] std::jthread - join 없이 사용하기📌 (0) | 2023.11.28 |